시계열 분야의 Anomaly Detection 에는 어떤 종류가 있는지 분류는 어떻게 하는지 감을 잡고 싶으신 분들은 한 번 해당 논문을 읽어보시면 좋을 것 같습니다. 논문을 읽은 목적은 다양한 환경과 상황의 시계열 데이터를 가지고 이상을 감지해야 하는 현실에서 어떤 아이디어를 가진 모델 또는 방법을 찾아 문제를 해결할 수 있을지 접근하기 위해 분류법을 먼저 서치하고자 하였습니다.
https://sci-hub.se/https://doi.org/10.1145/3444690
Sci-Hub | A Review on Outlier/Anomaly Detection in Time Series Data. ACM Computing Surveys, 54(3), 1–33 | 10.1145/3444690
↓ save Blázquez-García, A., Conde, A., Mori, U., & Lozano, J. A. (2021). A Review on Outlier/Anomaly Detection in Time Series Data. ACM Computing Surveys, 54(3), 1–33. doi:10.1145/3444690 10.1145/3444690
sci-hub.se
용어 정리
realized value : 확률적으로 현실화된 값 (realized value, 실험이 행해진 후의 값)
확률 변수 : 사건을 숫자로 대응시키는 사상(mapping) 또는 함수(function)로서 수학에서의 일반적인 변수와는 의미가 다르다. 확률 변수는 대문자로 나타내는데, 표본의 원소들은 개개가 각각의 확률변수로 표현된다. 모든 확률 변수는 분포를 갖는다. 즉, 확률적으로 현실화된 값(realized value, 실험이 행해진 후의 값)을 가지게 된다. 확률 변수를 이용한 결과 수식, 즉 확률 변수의 함수는 또 다른 확률 변수가 된다.
시리즈의 역학(dynamics)
(p.13) single time-dependent variable : 시간 독립 단일 변수?
논문 제목
A Review on Outlier/Anomaly Detection in Time Series Data (시계열 데이터의 이상값/이상 탐지에 대한 검토)
요약
최신 이상값 탐지 기법들에 대해 특징지을 수 있는 주요 측면들을 가지고 시계열 이상탐지에 대해 분류법을 제시하는 내용의 논문. 이상 감지 중에서도 세부 범위인 시계열 context 에서 비지도 이상값을 탐지하는 기술에 대해 체계적이고 포괄적인 최신 기술정보를 제공하는 것을 목표로 함.
1. Introduction
시계열은 순차적으로 기록되고 시간에 상관 관계가 있는 관측치로 구성된다. 시계열 데이터 마이닝은 이로부터 의미있는 모든 지식을 추출하는 것을 목표로 한다. Outlier detection 은 여러 분야에서 연구되고 있다. 예를 들면 신용카드 사기 탐지, 사이버 보안 침입 탐지, 업계의 오류 진단 등이 있다.
시계열의 이상값은 여러 의미를 가지는 단어이다. 예를 들면 Outlier는 anomalies, discordant observations, discords, exceptions, aberrations, surprises, peculiarities or contaminants 등의 단어들로 언급되곤 한다.
이상값은 결국 예상된 동작을 따르지 않는 관측값으로 생각할 수 있다. 시계열 이상값은 아래 그림처럼 다시 두 가지 의미를 가질 수 있다. 나누는 기준은 분석가의 목적, 관심, 고려되는 특정 시나리오에 기반한다.

만약 분석가 입장에서 이상값을 원하지 않는 데이터(Unwanted data)라고 판단할 수 있다. 이 경우 Data cleaning 을 진행한다. 노이즈, 오류, 원치 않는 데이터는 예측을 하는 것이 주 목적인 분석가에게 흥미롭지 않으므로 데이터 품질을 개선하고 다른 데이터 마이닝 알고리즘에서 사용할 수 있는 보다 깨끗한 데이터 세트를 생성하기 위해 이상값을 삭제하거나 수정해야 한다. 예를 들어 센서 전송 오류 등이 제거된다.
반면 분석가가 이상값을 흥미로운 현상 (Event of interest) 이라고 판단할 수 있다. 최근 몇 년동안, 특히 시계열 데이터 영역에서 분석가들은 특이하지만 흥미로운 현상을 탐지하고 분석하는 것을 목표로 하고 있다. 예측이 주 목표가 아니라 이상값 자체를 탐지하고 분석하는 것(예 :사기 탐지)이 목적인 것이다. 이러한 관측치들을 종종 이상현상(anomalies) 이라고 한다.
해당 article의 4가지 주요 기여
— 지금까지 시계열에서 비지도 이상탐지에만 초점을 맞춰 정보를 제공한 문헌, survey가 없었다. 거의 탐구되지 않았던 시계열 데이터에만 초점을 맞춘 포괄적인 기술 검토와 심층 분석을 제공한다.
— 기존 방법론의 가장 관련성이 높은 특성을 추출하여 시계열 데이터의 이상값 탐지 방법에 대한 새로운 분류(taxonomy)를 제안한다. 이 분류법은 시계열에서 이상값과 탐지에 대한 전체적인 이해를 제공하고 주어진 문제에 가장 잘 적응하는 기술 유형을 선택하는 데 도움이 될 것이다. 또한 각 기술을 특징짓는 다른 features 에 대한 세부 정보도 제공한다. 기존 조사는 완전한 분류를 제안하지 않으며 각 방법의 특성을 추출하지 않는다.
— 분석된 방법과 관련하여 공개적으로 사용 가능한 소프트웨어를 제공한다. 이것은 방법을 재현할 수 있게 해주므로 중요하다. 기존 관련 survey에는 이 정보가 없었다.
— 시계열에서 이상값 감지에 대한 몇 가지 향후 연구 방향을 찾는다.
논문의 구성
1장 - 본 연구에서 따랐던 방법론 설명
2장 - 시계열 데이터에서 이상값 검출 기법을 분류하기 위한 분류법 제안
3, 4, 5장 - 각각 점, 부분 시퀀스 및 시계열 이상값 탐지에 사용되는 서로 다른 기술 제시
6장 - 고려된 이상값 탐지 방법 중 일부에 대해 공개적으로 사용 가능한 소프트웨어가 제공
7장 - 결론을 내리고 추가 연구를 위한 몇 가지 영역 설명
1.1 METHODOLOGY
이 연구는 3가지 research 질문에 대답하려는 의도로 시작되고 조직되어 왔다.
(RQ1) 각 이상 탐지 방법을 정의하는 가장 중요한 특성이 무엇인가? 이에 기반해서 기존 기술을 어떻게 분류할 수 있는가?
(RQ2) 어떻게 기존 기술들이 시계열에서 연속적이고 시계열 이상값 포인트를 탐지하는가? 이 방법의 주요 차이점은 무엇인가?
(RQ3) 시계열에서의 이상값 탐지를 위한 소프트웨어 패키지가 공개적으로 사용할 수 있는 것이 있는가? 그것이 실행하는 방법의 유형이 무엇인가?
2. A TAXONOMY OF OUTLIER DETECTION TECHNIQUES IN THE TIME SERIES CONTEXT (시계열 분야에서의 이상값 감지 기술 분류법)
시계열데이터의 이상감지 기술은 input data의 종류, 이상값 종류, 방법의 특성에 따라 매우 다양하다. 그림 2에서 분류의 개요를 나타낸다. Input data, Outlier type, Nature of the method 3가지로 나누어 설명.

2.1 Input data
각 관측치 xt는 특정 랜덤 변수 Xt의 실현값(real-valued observation) 이라고 가정.
Definition 2.1 일변량 시계열(Univariate time series)
: 양의 정수 집합 T (t ∈ T ⊆ Z+) 에 속하는 특정한 시간 t 에 수집된 각각의 실관측치 xt를 시간 순으로 나열한 집합.

Definition 2.2 다변량 시계열(Multivariate time series)
: 양의 정수 집합 T (t ∈ T ⊆ Z+) 에 속하는 특정한 시간 t 에 수집된 각각의 k개의 실관측치 xt 를 시간 순으로 나열한 k차원의 벡터 집합.

임의의 시간 종속 변수 Xjt 의 Xj 는 각 차원에서 단변량이고 벡터 xt에 있는 각 관측치 xjt는 Xt = (X1t,...,Xkt) 에 있는 임의의 시간 종속 변수Xjt 의 확률적으로 현실화된 값(realized value, 실험이 행해진 후의 값)이다. 이 경우 각 변수는 과거 값뿐만 아니라 다른 시간 종속 변수에도 의존할 수 있다.
2.2 Outlier type
두번째 갈래는 이상값 유형으로 이상감지를 설명하는 분류입니다.
Point outliers
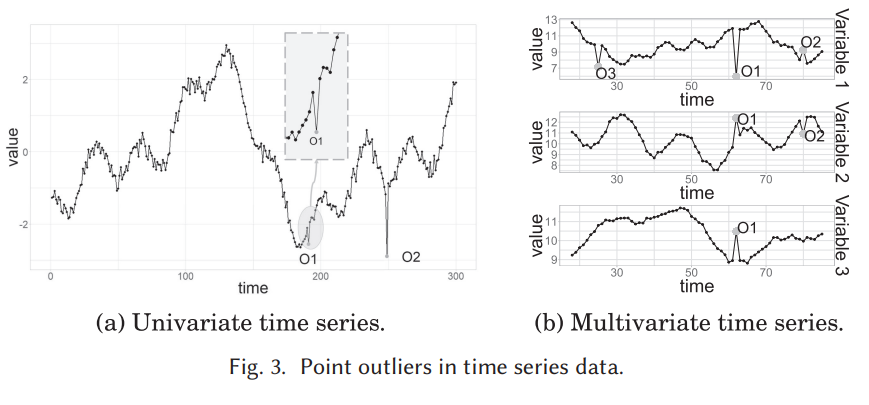
시계열의 다른 값(global outlier) 과 비교했을 때나 인접한 point (local outlier)와 비교했을 때, 특정 시점에 비정상적으로 동작하는 데이터. 각각 하나 이상의 시간 종속 변수에 영향을 미치는지 여부에 따라 포인트 이상은 단변량 또는 다변량일 수 있음. 예를 들어, 그림 3의 세 변수로 구성된 다변량 시계열 3에는 단변량(O3)과 다변량(O1 및 O2) 지점 이상값이 모두 있다.
Subsequence outliers.
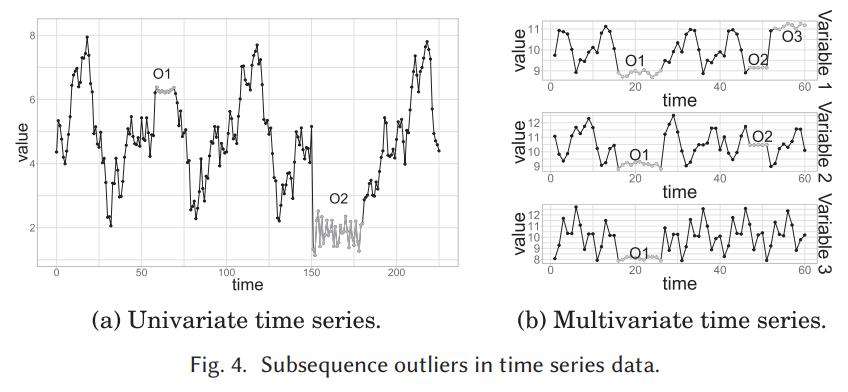
각 관측이 개별적으로 반드시 포인트 이상값이 아니더라도 공동 행동이 비정상인 연속적인 시점을 의미. 하위 시퀀스 이상값은 전역 또는 로컬일 수도 있으며 하나(단변량 하위 시퀀스 이상값) 이상(다변량 하위 시퀀스 이상값) 시간 종속 변수에 영향을 줄 수 있다. 그림 4 는 단변량(그림 4의 O3 4) 및 다변량(그림 4(b)의 O1 및 O2 )하위 시퀀스 이상값의 예를 제공. 후자가 반드시 모든 변수에 영향을 미치는 것은 아니다(예: 그림 4(b)의 O2).
Outlier time series
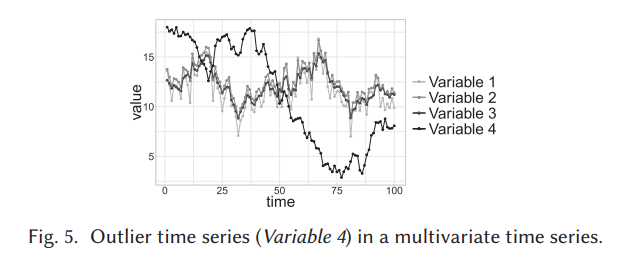
전체 시계열도 이상값일 수 있지만 입력 데이터가 다변수 시계열인 경우에만 감지할 수 있음. 그림 5는 네 개의 변수로 구성된 다변량 시계열에서 특이치 시계열의 예를 보여준다. 변수 4의 동작은 나머지 동작과 유의하게 다름.
2.3 Nature of method
방법의 특성을 기준으로 이상 감지 분류를 하는 것. 감지하는 방법이 일변량 탐지인지 다변량 탐지인지로 나뉜다.
일변량 탐지 방법 : 변수 사이에 존재하는 종속성을 고려하지 않고 이상을 감지하는 것
다변량 탐지 방법 : 변수 사이에 존재하는 종속성을 고려하여 이상을 감지하는 것.
만약 Input data 가 단변량 시계열이라면 항상 단변량 탐지만 해야 하므로 이 관점으로 분류를 할 수 없고 Input data 가 다변량 시계열인 경우에만 이상감지 방법들을 분류할 수 있음.
3. POINT OUTLIERS

point 이상값 감지는 시계열 영역에서 가장 일반적인 이상감지 작업.
3.1 단변량 시계열, 3.2 다변량 시계열 데이터 모두에서 point outlier를 감지하는 기술을 다룰 것.
Point outlier 감지 문제와 관련된 특성 2개 : " Temporality(시간성)" , " Streaming / Non-streaming "
" Temporality(시간성) " 특성을 고려하면
1) 관측치의 시간 순서를 고려하는 Point 이상감지와
2) 관측치의 시간 순서를 무시하는 Point 이상감지로 나눠짐.
만약 시계열의 관측치 순서를 섞어서 이상을 감지한다면?
1) 시간 창(time window)을 사용하는 방법을 사용한 경우, 시간 창 안의 관측치끼리 섞을 경우 원 시계열에서 감지할 때와 동일한 이상 감지 결과. 그러나 전체 시계열 관측값을 섞으면 결과가 다르다.
2) 원 시계열에서 감지한 이상과 동일한 이상을 감지
" Streaming / Non-streaming ( 순차적으로 들어오는 / 그렇지 않은 ? ) " 특성을 고려하면
Streaming :
1) 데이터가 들어오자마자 새 데이터가 더 들어오길 기다리지 않고 바로 이상을 감지할 수 있거나 (고정 모델을 사용)
2) 전체 모델을 재학습하거나 새로운 정보를 가지고 점진적 방법으로 모델 업데이트하여 이상을 감지함.
Non-streaming :
만약 새로운 스트리밍 데이터가 도착했을 때 이상에 관한 결정을 내릴 수 없는 경우에는 포인트 이상값 탐지 기술이 적용되지 않는다고 본다.
분석된 포인트 이상값 탐지 기술의 대부분은 스트리밍 컨텍스트에 적용할 수 있으며 전체 시계열을 순서가 지정된 시퀀스로 간주하거나 시간 창을 사용하여 데이터의 시간성을 고려합니다. 따라서 스트리밍 환경에서 적용할 수 없거나 데이터의 시간 정보를 완전히 무시하는 방법에 대해서만 이 축(point outlier) 을 참조. 많은 기술이 이론적으로는 스트리밍 시계열을 처리할 수 있지만 스트리밍 변화에 점진적으로 적응할 수 있는 기술이 거의 없다.
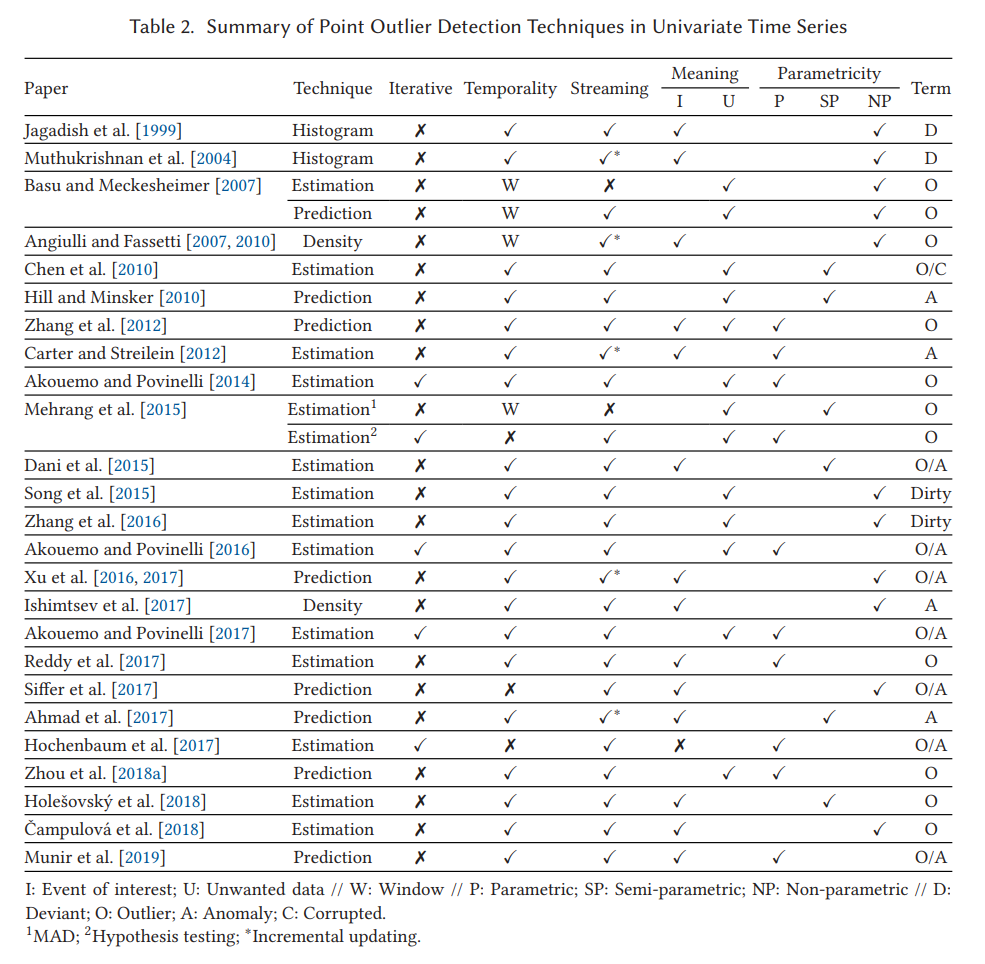
3.1 Univariate Time Series
단변량 시계열의 이상점 감지 수단 유형은 아래와 같이 나눌 수 있음
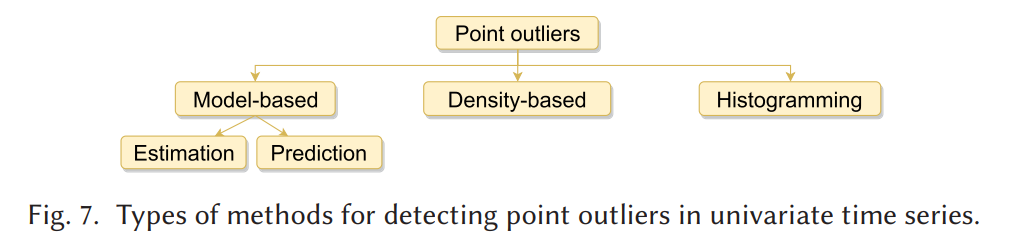
단일 시간 종속 변수가 고려된다면 단변량 이상 감지.
가장 대중적이고 직관적인 Point Outlier 정의 : 예상 값에서 크게 벗어나는 포인트
Model-based 이상점 감지
여기서 가장 대표적으로 알아야 할 개념이자 식은 아래와 같음

가장 흔한 접근법이 (1) 번 식을 기반으로 한 모델 기반 이상 탐지이다. 아래 Fig 8 은(1) 로 계산한 그림.
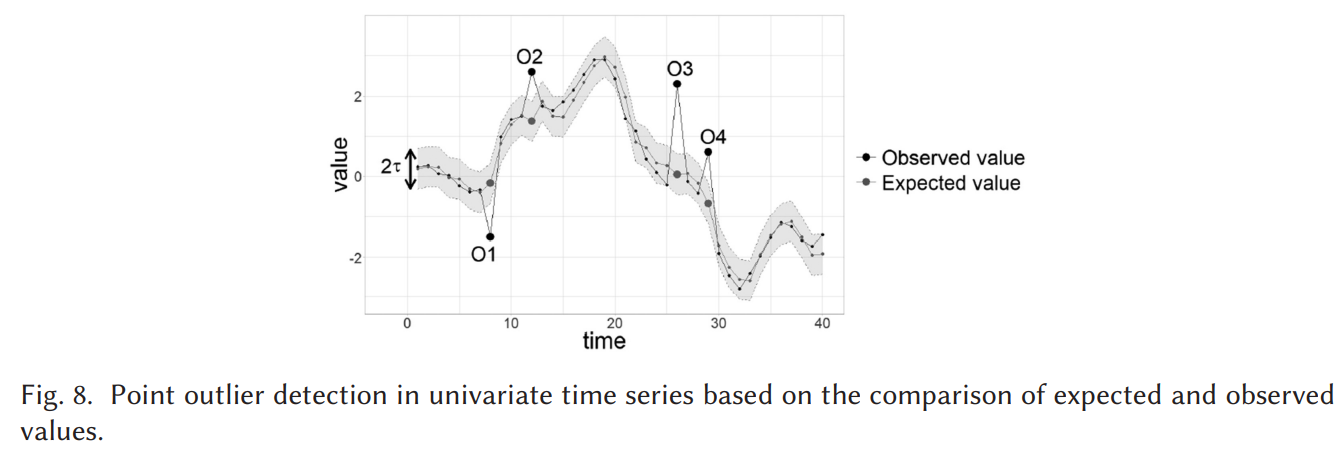
각 기술들이 기대값 xt hat 과 threshold인 타우를 다 다르게 계산하겠지만 모두 명시적으로든 암묵적으로든 모델에 적합하는 것을 기반으로 한다.

Table1 내용처럼 크게 1) 추정모델 기반 2) 예측모델 기반 방식이 있음.
1) 추정모델 기반 : 예측값을 구할 때 이전과 이후의 관찰을 이용한 경우 (과거 현재 미래 데이터 모두 이용)
2) 예측모델 기반 : 예측값을 구할 때 이전 관찰만 이용한 경우 (현재 시점 t에 대해 과거 관측 데이터만 이용)
실제로 새로운 데이터가 들어오는 순간에 2) 방식으로 이상값 여부를 즉시 알 수 있어서 streaming 시계열에 2) 사용 가능.
2) 예측모델 기반 방법 중 일부는 고정 모델을 사용하기 때문에 시간이 지남에 따라 데이터에서 변경 사항이 발생하면 적응할 수가 없음.
Density-based 이상점 감지
지금까지는 모두 수식 (1) 을 기반으로 했지만 이 아이디어를 기반으로 하지 않는 이상 감지들도 있음.
두번째 카테고리인 밀도 기반 이상감지는 point with less than 타우 neighbors is outlier이다. 즉, 그 점들로부터 거리 R 안에 있는 점 개수가 타우 개 미만이면 이상값이라는 것. d 는 일반적으로 유클리드 거리이고 xt 는 타임 스탬프 t에서의 데이터 포인트를 의미, X는 데이터 포인트 집합이고 R은 양의 정수 집합의 원소.
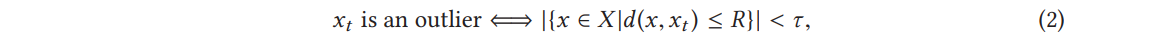
시간이 아닌 데이터에서 밀도 기반 이상감지가 광범위하게 다뤄져 왔지만 이웃이라는 개념은 시계열에서 훨씬 복잡함. 왜냐하면 그 데이터는 순서화되었기 때문임. Angiulli and Fassetti [2007, 2010] and Ishimtsev et al. [2017]가 제안한 방법으로 스트리밍 시계열에서 새 값이 도착했을 때 이상인지 여부를 결정할 수 있는데 이 때 포인트는 윈도우의 이상값이 될 수 있음. 그림 9를 보면 O13은 이상값이지만 I13은 이상값이 아니게 됨. t=13 에서 S4가 이상값이 될 수 없는 이유는 해당 포인트가 창 내에서 적어도 타우 연속 이웃을 가지기 때문.

히스토그램 이상점 감지
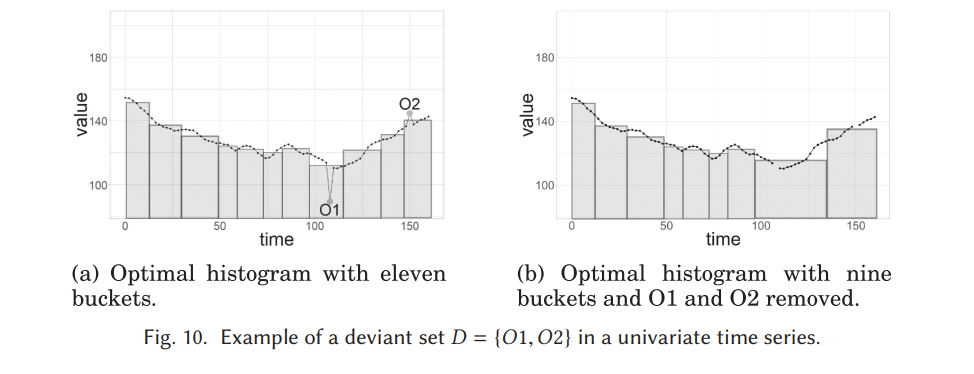
이 유형의 방법은 단변량 시계열에서 어떤 점을 제거했을 때 원본보다 낮은 오차의 히스토그램 표현이 나타나는 점을 감지함. (그림 10 참조). 버킷 수가 줄어든 것도 낮은 오차로 보는 듯.
히스토그램은 각 버킷 내의 값의 평균을 계산하여 만들어지며, 관측치의 순서가 유지된다.
추가적인 사항
추가로 이상값을 찾기 위한 방법의 모수성을 기준으로 나누면
모수적 기법 : 분석 중인 현상의 기본 분포가 모수적 패밀리에 속한다고 가정하고 주어진 데이터에서 해당 모수(고정된 수)를 추정.
비모수적 기법 : 모델 또는 분포군이 선험적으로 정의되지 않고 대신 주어진 데이터에서 결정되며 유연한 수의 매개변수를 가짐.
반모수적 기법 : 매개변수적 접근과 비모수적 접근을 모두 결합하는 방법. 반모수적 기법은 일반적으로 임계값을 정의할 때 잔차가 비모수적 접근 방식으로 얻어지는 경우에도 잔차에 대한 분포를 가정함.
대부분의 모델 기반 기술은 모수적 또는 반모수적임. 일반적으로 여기서 저자가 outlier라고 언급하거나 설명하려는 기술들은 시간성을 고려하고 스트리밍 컨텍스트에 적용될 수 있음. 또한 몇 가지 반복 방법(iterative)은 원하지 않는 데이터를 감지하고 시계열의 품질을 개선하는 것과 관련 있음.
스트리밍 시계열에서 추정 방법을 적용할 때의 주의점
마지막으로 도착한 데이터 지점 xt(표 1에서 k2 = 0)에 대한 후속 관측을 사용하지 않는 추정 방법을 주의해야 함.
이론적으로는 스트리밍 context 에 이 기술을 적용할 수 있지만, 이러한 방법은 마지막으로 수신된 관측치(xt)와 다른 과거 정보를 사용하여 기대값(xt)을 계산한 다음 특이치인지 여부를 결정하게 됨. 따라서 새로운 포인트가 도착한 후에 몇 가지 계산을 수행해야 하는데 이 계산의 비용이 (이 기사나 다른 원본 연구에서 분석되지 않은) 복잡성에 따라 다르겠지만 항상 빠른 응답을 보장하진 않음.
-> 이러한 스트리밍 시계열에서 후속 관측을 쓰지 않는 상황에는 예측 방법을 권장함.
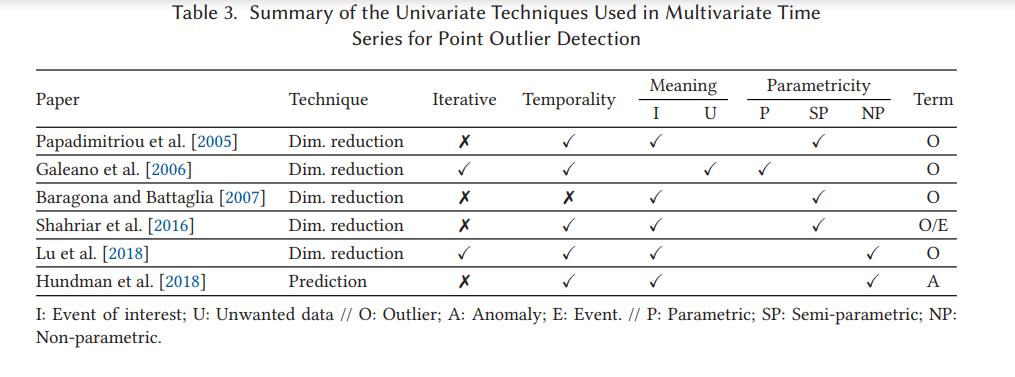
3.2 Multivariate Time Series
입력 시계열이 단변량 시계열이 아닌 상관관계가 있는 변수가 있는 다변량 시계열인 경우.
일변량 시계열의 경우와 달리 다변량 시계열에서 포인트 이상값을 식별하는 데 사용되는 감지 방법은 2가지. (3.2.1, 3.2.2 참고)
또한 다변수 시계열의 포인트 이상값은 하나(단변수 포인트) 또는 둘 이상의(다변수 포인트, 시간 t) 변수에 영향을 줄 수 있음(그림 3(b) 참조).
3.2.1 Univariate Techniques
다변량 시계열이 하나 이상의 시간 종속 변수로 구성되어 있는 경우.
1) 변수 간에 존재할 수 있는 종속성을 고려하지 않고 각 변수에 대해 단변량 분석을 수행하여 단변량 포인트 이상값을 탐지.
3.2.1 에서 검토한 모든 방법은 출력을 제공하기 위해 미래 데이터가 필요하지 않기 때문에 슬라이딩 윈도우를 사용하여 스트리밍 컨텍스트에서 포인트 이상값을 이론적으로 감지할 수 있음.
예시 1 - Hundman et al. [2018] 은 차원 축소에 기반한 기술과 달리 분석할 새로 도착한 지점을 모델 구성에 사용하지 않기 때문에 가장 잘 작동. 그러나 증분 버전은 제안되지 않음.
이 방법의 문제 : 일변량 기법을 각 시간 종속 변수에 적용할 때 변수 간의 상관 종속성을 고려하지 않기에 정보가 손실될 수 있음.
극복할 수 있는 방법은 아래 두 가지 방법들이 존재
2) 입력 다변수 시계열을 더 낮은 차원의 시계열이자 상관되지 않은 변수 집합으로 줄임
다변량 시계열에 전처리를 적용하여 새로운 비상관 변수 집합을 찾는 방법이다. 이 전처리를 거쳐 낮은 차원의 표현으로 단순화된 시게열 각각에 고도로 발달된 일변량 탐지 기술을 활용할 수 있어서 좋음.
* 주로 사용하는 전처리 방법 : 차원 축소 기술 기반
예시 1 - Papadimitriou et al. [2005]는 새로운 독립 변수를 결정하기 위해 증분 주성분 분석(PCA) 알고리즘을 제안. 이 경우 적용되는 사후 일변량 포인트 이상값 탐지 기술은 자기회귀(AR) 예측 모델을 기반으로 함.
예시 2 - Galeano et al. [2006]은 이상치를 식별하기 위한 최상의 투영을 찾는 것을 목표로 하는 투영 추적으로 차원을 줄이는 것을 제안. 최적의 방향이 투영된 시계열의 첨도 계수를 최대화하거나 최소화하는 방향임을 수학적으로 증명함.
예시 3 - [Fox 1972; Chen and Liu 1993]에서는 다변량 포인트 이상값 탐지를 위해 각 투영된 단변량 계열에 반복적으로 변량 통계 검정을 적용.
예시 4 - Baragona와 Battaglia[2007]는 관찰할 수 없는 독립적인 비가우스 변수 세트를 얻기 위해 ICA(Independent Component Analysis)를 사용할 것을 제안함. 식 (1)이 xθit = μi 및 θi = 4.47µi에 대해 만족될 경우 특이치는 각 새 시리즈에서 독립적으로 식별됩니다. 여기서 μi는 평균이고 θi는 i번째 새 변수의 표준 편차입니다.
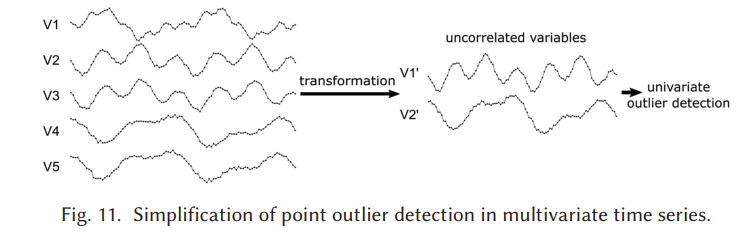
=> 생기는 질문 : "단순화된 새 series는 초기 입력 변수의 조합이므로 식별된 이상값은 다변량입니다." 즉, 둘 이상의 변수에 영향을 줍니다. 라고 하는데 그렇다면 어떤 변수가 이상했는지를 알 수 있는 방법은 없겠네? 해당 시점이 이상했다는 사실만 알 수 있음. => 만약 저차원으로 줄인 V2'를 가지고 원 변수들인 고차원으로 역변환하는 방법이 있다 하더라도 별 의미가 없을 거고. 1) 번 방법은 원인분석이 필요한 환경이라면 사용하기 어려울 듯.
3) 입력 다변수 시계열을 상관되지 않은 변수 집합이 아닌 단일 시간 종속 변수로 줄임.
예시 1 - Luet al. [2018] 시간에 따라 인접한 벡터 간의 상호 상관 함수를 사용하여 변환된 일변량 계열을 정의합니다. 즉, xt −1 및 xt . 점 이상값은 이 새 시리즈에서 인접한 다변량 점과 낮은 상관 관계를 갖는 것으로 반복적으로 식별됩니다. 임계값 τ 는 다중 레벨 Otsu의 방법에 의해 각 반복에서 결정됨.
예시 2 - Shahriar et al. [2016] 은 또한 고려되는 애플리케이션 도메인을 위해 특별히 설계된 변환을 사용하여 다변량 시계열을 단변량 시리즈로 변환합니다. 포인트 이상값은 방정식(1)과 3-시그마 규칙을 사용하여 식별됨.
* 차원 축소 시 시간성을 고려할 수 있는지?
Shahriar et al. [2016] 및 Lu et al. [2018] 변환 단계에서 시간성을 포함하는 방법을 사용합니다. 차원이 감소되지 않는 다른 접근 방식에서 시간성은 적용된 감지 방법에 직접적으로 의존합니다.
3.2.2 Multivariate Techniques
일변량 기법과 달리 이 섹션에서는 이전 변환을 적용하지 않고 여러 시간 종속 변수를 동시에 처리하는 다변량 방법을 분석함.
모델 기반 방법
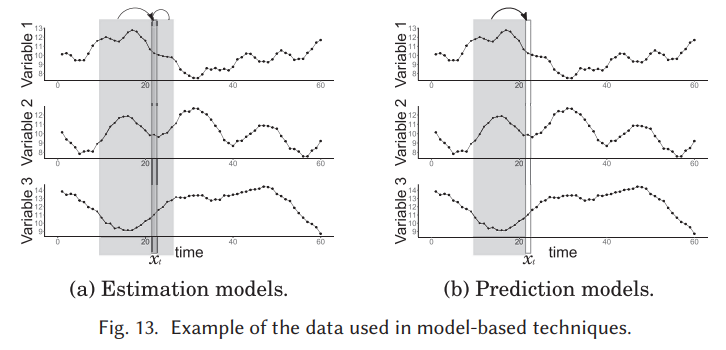
단변량 시계열에서처럼 모델 기반 기법을 사용하여 다변량 시계열에서 점 특이치를 탐지할 수도 있다. 이 그룹 내의 방법은 원래 입력 시계열에서 예상되는 값을 얻기 위해 시리즈의 역학(dynamics) 을 포착하는 모델을 적합시키는 것에 기반한다. 그런 다음, 사전 정의된 임계값 τ 의 경우, ||xt − xˆt || > τ ,이면 특이치가 식별되며, 여기서 xt는 실제 k차원 데이터 포인트이고 xt는 기대값임. 이는 일변량 시계열의 모델 기반 기법에 대해 주어진 정의를 일반화한 것이며 직관은 반복된다는 점에 유의. (방정식 (1)과 표 1 참조). 실제로 xˆt는 과거, 현재 및 미래 값을 사용하는 추정 모델 또는 과거 값만 사용하는 예측 모델을 사용하여 얻을 수 있다(그림 13 참조).
1) 추정 모델 기반
자동 인코더는 추정 모델 기반 방법에서 가장 일반적으로 사용되는 방법 중 하나. 자동 인코더는 정규성의 기준으로 사용되는 훈련 세트의 가장 중요한 특징만 학습하는 신경망의 한 유형. 특이치는 대표적이지 않은 특징에 해당하는 경우가 많기 때문에 자동 인코더는 이를 재구성하지 못해 방정식(4)에서 큰 오류를 제공함.
예시 1 - Sakurada와 Yairi[2014]는 자동 인코더의 입력이 시계열의 단일 다변량 지점인 이 방법을 사용. 각 변수 내의 관측치 간의 시간적 상관 관계는 이 근사치에서는 고려되지 않는 한계 있음
예시 2 - 시간 의존성을 설명하기 위해, Kieu et al. [2018] 는 자동 인코더를 적용하기 전에 겹치는 슬라이딩 윈도우 내에서 기능(예: 수학적 기능)을 추출할 것을 제안함.
예시 3 - Su et al. [2019]는 게이트 순환 단위(GRU)를 가진 VAE(Variational AutoEncoder)를 기반으로 더 복잡한 접근 방식을 제안. 모형의 입력은 그에 선행하는 관측치 xt와 l을 포함하는 일련의 관측치. 출력은 재구성된 xt(xtt). 또한 극한값 이론을 적용.
2) 예측 모델 기반
다변량 시계열에 모형을 적합시키기도 하지만, 과거 값을 기반으로 한 미래에 대한 예측으로 기대 값을 만들기도 함.
예시 1 - 상황별 은닉 마르코프 모델(CHMM)은 다변량 시계열에서 시간 의존성과 변수 간의 상관 관계를 점진적으로 포착 [Zhou et al. 2016]. 시간 의존성은 기본 HMM에 의해 모델링되고 변수 간의 상관관계는 HMM 네트워크에 추가 계층을 추가하여 모델에 포함된다.
예시 2 - 섹션 3.1에서 언급된 DeepAnt 알고리듬[Munir et al. 2019]은 CNN 예측 모델을 사용하여 다변량 시계열에서 포인트 특이치를 감지할 수도 있다. 모델이 학습되면 이전 관측치의 창을 입력으로 사용하여 다음 타임스탬프가 예측됨.
이러한 모든 추정 및 예측 기반 방법은 이론적으로 슬라이딩 창을 사용하는 스트리밍 컨텍스트에서 사용될 수 있다. 일변량 시계열과 마찬가지로 추정 기반 방법은 적어도 새로 도달한 점 xt(표 1에서 k2 = 0)를 고려해야 하므로 예측 기반 기법이 스트리밍 방식으로 특이치를 탐지하는 데 더 적합하다. 또한 이러한 모델 기반 기술은 모두 고정 모델을 사용하며, Zhou 등의 제안을 제외하고 시간에 따른 변화에 적응하지 않는다. [2016], 이것은 점진적으로 업데이트된다.(?)
dissimilarity-based methods (차이점 기반 방법)
이러한 기법은 모형을 적합시킬 필요 없이 다변량 점 또는 그 표현 사이의 쌍별 불일치를 계산하는 데 기초함. 따라서, 사전 정의된 임계값 λ에 대해, xt는 다음과 같은 경우 점 특이치이다.
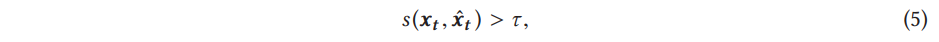
이러한 방법은 일반적으로 원시 데이터를 직접 사용하지 않고 다른 표현 방법을 사용합니다. 예를 들어 Cheng 등이 있습니다. [2008, 2009]는 노드가 시리즈의 다변량 지점인 그래프와 RBF(Radiary Basis Function)로 계산된 노드 간의 유사성 값을 가장자리에 사용하여 데이터를 나타낸다. 아이디어는 그래프에서 무작위 보행 모델을 적용하여 다른 노드와 다른 노드(즉, 그래프에서 거의 액세스할 수 없는 노드)를 감지하는 것이다. 대조적으로, Li 등은. [2009]는 변수들 사이의 역사적 유사성과 불일치 값을 벡터에 기록하는 것을 제안한다. 목적은 시간에 따른 연속 점의 불일치를 분석하고 ||.||1을 사용하여 변화를 감지하는 것이다.
추가적인 사항
대부분이 다변량 점 특이치를 찾더라도 일부는 다변량 정보를 사용하여 단일 변수에만 영향을 미치는 점 특이치(즉, 일변량 점 특이치)를 식별합니다. 분석된 모든 기법은 반복적이지 않으며 특이치는 연구자가 관심 있는 사건을 나타낸다. 또한, 대부분의 방법은 시간 정보를 고려하는 셔플된 버전의 시계열에 적용할 경우 다른 결과를 얻는다. 이러한 모든 방법은 스트리밍 컨텍스트에서 특이치를 감지할 수 있지만, 새로운 데이터가 도착할 때 증분되거나 업데이트되는 방법은 거의 없다. 모델 기반 기법의 대부분은 파라메트릭 또는 준파라메트릭임 히스토그램 또는 유사성에 기반한 모든 기술은 비모수적임.
4. SUBSEQUENCE OUTLIERS


댓글